The query engine
Two cooperating pieces: a matcher that decides whether a document satisfies a filter, and a planner that decides how few documents the matcher needs to see. The planner's rules fit on this page — by design. There is no cost model and no statistics; transparency is the feature.
The filter language
{ field: literal } // equality (dotted paths work)
{ field: { $eq | $ne | $gt | $gte | $lt | $lte: v } }
{ field: { $in: [v, ...] } }
{ $and: [f, ...] } { $or: [f, ...] }Matcher semantics worth knowing:
- Numbers compare numerically across types —
{a: 1}matches an Int32, Int64, or Double 1. - Everything else is type-bracketed:
$gt: 5never matches a string; mismatched types simply fail the predicate rather than erroring. - Missing fields match only
$ne. (MongoDB treats missing as null for equality; BisonDB doesn't — a documented divergence, consistent with missing fields being absent from indexes.) - Dotted paths traverse nested documents, not arrays.
Planner rules — all of them
- Filter contains
$orat the top level → full scan. - Equality on
_idwith an ObjectId → index_point: one_id-tree lookup. - Otherwise, the first field (in filter order) that has an index and an equality or range constraint (
$gt/$gte/$lt/$lte, possibly combined under$and) → index_range. - Nothing qualifies → full scan via the
_idindex.
That's the whole planner. Two consequences follow:
Residual predicates. An index scan only enforces its field's constraint. Every fetched document is re-checked against the complete filter, so {pop: {$gte: 40000}, state: "NY"} walks the pop index and filters state per document. Correctness never depends on the planner being clever.
Range bounds come from key encoding. $gte: v seeks to encode(v); $gt: v seeks to encode(v) ‖ FF, stepping over every composite key that starts with that exact value. An open-ended range stops at the type-class tag boundary — $gt: 5 ends where numbers end, so it cannot leak into strings. Type bracketing falls out of the encoding rather than being a special case.
explain, annotated
{
"plan": "index_range", // scan | index_point | index_range — rule 1–4 above
"index": "pop", // present when an index was chosen
"docsExamined": 1015, // documents fetched from the log and run through the matcher
"docsReturned": 1015 // documents that passed the full filter
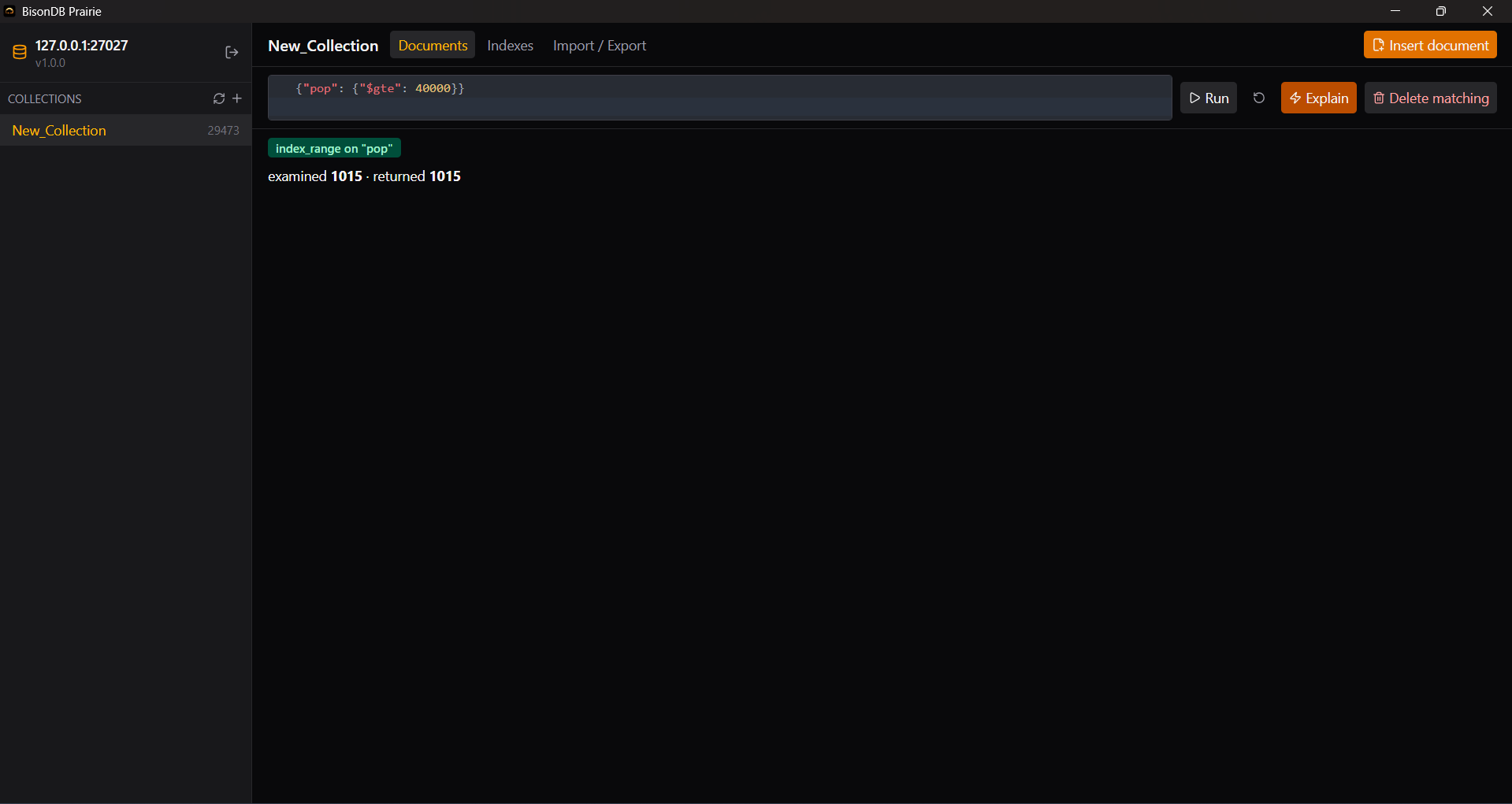
}How to read the pair: examined == returned means the index bounds were exact — the residual check rejected nothing. examined >> returned with a scan plan is the signature of a missing index. examined > returned on an index_range means residual predicates are doing real filtering — expected for multi-field filters, since indexes cover one field.
scan examined 29470 · returned 1015 ← before createIndex('pop')
index_range examined 1015 · returned 1015 ← afterThe same plan surfaced in Prairie, reading the explain response over the wire protocol:
Writes through the same path
deleteMany(filter)runsfind, then deletes by_id— the planner accelerates deletes exactly as it does reads.updateOne(filter, {$set: ...})finds one match, applies the$set(dotted paths create intermediate documents), and appends the new version; every index updates in the same critical section.$setis the only update operator — field removal doesn't exist in the protocol.count(filter)is implemented asexplain().docsReturned— counting is a query that discards its results.
What's deliberately missing
Sorting (other than natural _id-index order), projections, compound indexes, $not, aggregation. Each was cut to keep the rule list above complete and honest rather than "mostly accurate." The FAQ discusses what adding them would take.